
ô ô LVSÌ₤ÌÍ£¤Í´real serverÕÓƒÊð¿ð¡ÓÐÍ ñÌÕ¨ÌˋÍÝÌÏÍÍ₤Ó´ÌÏÓÒÌÌÍÀÍ´ÿ¥ÕÍ¡¡Ìð£˜Óϯð¿ð¡¤ãÒÇÒ§§ÍÒÀÀãÌÍÀÍ´ÐÌÍÀÍ´ÓÕÓƒÊÌÑÌÍ₤¿Ó´ÌñÒÒ´Ì₤ÕÌͤÎÿ¥Ó´Ìñð¡ÕÓƒÊÓ°£Ó£ð¤Êð¤ÌÑÿ¥Í¯ÝÍð¡Íð¡ˆÕ¨ÌÏÒ§ÓÒÌÌÍÀÍ´ð¤Êð¤ð¡Ì ñÿ¥Ò¢Í₤¿ÌÌÑÒƒÍÊÏÒÏÌ´ÀÓÌÍÀÓ¨Ó¿ÿ¥ÌÌÍÊÏÓÍ¡ÛÍˋÐ
ô ô ô ÍÛÕ ÌÍÀÍ´ÿ¥real serversÿ¥ÍÒÇÒ§§ÍÒÀÀÌÍÀÍ´ÿ¥LVSÓÙÿ¥ÕÒ¢Õ¨ÕÓLANÌÒ Í´Í¯Óð§Ó§Ûð¡ÍÌÈÓWANð¤Ó¡ÕƒÌËÐÒÇÒ§§ÍÒÀÀʹͯÒ₤ñÌÝÍÍÓ£ð¡ÍÓserverÿ¥ÒÛˋÍÊð¡ˆserverÍ¿ÑÒÀÓÌÍÀÿ¥ÓÒçñÌËÍÌ₤ð¡ð¡ˆIPð¡ÓÒÌÌÍÀÿ¥Ò₤ñÌÝÍÍÌÑÍ₤ð£Ëð§¢Ó´Í¤ð¤IPÓÒÇÒ§§ÍÒÀÀÌÌ₤ÿ¥ÌÒ ð§¢Ó´Í¤Ó´ÍÝÕÂÓÒÇÒ§§ÍÒÀÀÌÌ₤ÿ¥TCP,HTTPÿ¥ÐÓ°£Ó£ÓÌˋÍÝÿ¥Í₤ð£ËÕҢʹÕÓƒÊð¡ÙÍÂÐÍ ÒÓ¿ÿ¥real serverÿ¥ÌËÍÛÓ¯ÿ¥Ò¢Õ§Ì₤ÕÌÓÿ¥ÍÛÌðƒð¤ÒÓ¿ÌÇ£ÌÏÌÈÌç̤ÍÑÐÍÛÌÊÒ¢Ó´ÍÊÝÌÌÈÌçÿ¥Í¿ÑÕͧÕÌ¯Õ Ó§ÛÓ°£Ó£Ð
ô
ð¡Ðð¡¤ð£ð¿ð§¢Ó´LVS
ô ô ÕÓð¤ÒÓ§ÓÕ¨ÕÍÂÕ¢ÿ¥ÕÈð¿ð¤ÒÓ§ÓÌçÕð¿ÌËÍÏÍÂÍ ÿ¥serverÓÒÇÒ§§ð¿Õð¿Í Õÿ¥Ó¿Í¨Ì₤ð¡ð¤Ì₤ÒƒÌçÒÀÓwebÓ¨Ó¿ÿ¥ÍÛ̓ÍÛ¿ÌͯÝð¡Í ˆÒÇÕÐð¡¤ð¤ÒÏÈÍ°ÌÍÀÍ´ÓÒ¢Ò§§ÕÛÕÂÿ¥Ì2ÓÏÌ¿ÌÀÐð¡ð¡ˆÌ₤ÍserverÌ¿ÌÀÿ¥Í°ÍÓ¤ÏserverÓÓˋÓÕ Ó§Ûð£ËÌðƒÌÇÕ¨ÓÌÏÒ§ÿ¥ð§Ì₤ͧÒ₤ñÌÝÕð¡ÌÙÍÂÍ ÿ¥ÍÒÎÕÂð¡ÇÓ£ÏÓ£ÙÍÓ¤ÏÓÕÛÕÂÿ¥ÍÓ¤ÏÓÀ˜ð£ÑÓÒ¢Ó´Ì₤ÒƒÍÊÌÿ¥ÕÒÎÍ̤ÿ¥Òð¡Ì̘҃ըÿ¥Ó£Í§Íð¡ˆserverÓÍÓ¤ÏÌ₤ÌÓÑÕÂÓÿ¥Ìð£˜ð¡Ò§ð¡ÓÇÒ¢Ì ñð¡Í£ÿ¥ÍÎð¡ˆÌ¿ÌÀͯÝÌ₤ÍÊserverÍÊÍð§¢Ó´ÿ¥Í°Ìð£˜Í¡¡Ò₤ÇÓÕÓƒÊÌÑÌÿ¥Ìð£˜ð§¢Ó´ÍÊð¡ˆÍ£ð£ñÓserverÌÍ£¤ð¡ð¡ˆÕÓƒÊÿ¥ÒÛˋÍÛð£˜Í¿ÑÒÀÌðƒÌÍÀÿ¥Í§webÓ¨Ó¿ÓÒÇÒ§§ÍÂÍ ÿ¥Ìð£˜ÍˆÕÒÎÓÛÍÓÍÂÍ ð¡ð¡ˆÌÒ ÍÊð¡ˆserverÍ°Í₤ÿ¥ÌÏð£ñÌ₤̓ըÿ¥Ìð£ËÍ´ÌÌÑÍÊÏÍÍÍ¡Í¥ÌÍÀÌÑÿ¥Ò¢ÓÏÌ¿ÌÀÌÇÍ ñÌÌˋÍÝÌÏÐ
ô
ô ô ÌÍÎð¡Í ÓÏÌ¿Í¥ÌËÌÍ£¤ÍÍ¡Í¥ÌÍÀÍ´ÿ¥
ô ô 1ÿ¥Í¤ð¤DNSÓÒÇÒ§§ÍÒÀÀÕÓƒÊ
ô ô Ò¢ÓÏÌ¿Í¥Ì₤ÌÍ£¤ÍÍ¡Í¥Ó§Ó£ÌÓÛÍÓÌ¿Í¥ÐDNSÓ°£Ó£Í₤ð£Ëͯð¡ð¡ˆÍÍÒÏÈÌͯÍÊð¡ˆð¡ÍÓIPͯÍð¡ÿ¥Í§DNSÌÍÀÍ´ÌÑͯÍÍÒÏÈÌÒ₤ñÌÝÌÑÿ¥Ì₤ÍÎÍÛÂÌñÓ¨₤̘ͯÌýÀÌÍÍÓÒÏÈÌð¢ÀÌ₤ÿ¥ÿ¥DNSÌÍÀÍ´Í¯Ì ¿ÌÛүͤÎÓÛÌ°ÿ¥Ì₤ÍÎÒ§ÛÒ₤Âÿ¥ÕÌˋð¡ð¡ˆIPÒ¢ÍÓ£Ò₤ñÌÝÓ¨₤ÿ¥ÓÝ̘ͯDNSͯÌÙÊÒÏÈÌð¢ÀÌ₤Ó¥ÍÙð¡ÍÛÓÌÑÕÇÿ¥TTLÿ¥ÿ¥ÌÙÊÍÍÛÂÌñÓ¨₤Í₤¿ÌÙÊÍÍÓÒ₤ñÌÝͯð¥ð§¢Ó´ÌÙÊIPð§ð¡¤ÓÛÌ Í¯ÍÐ
ô ô Í₤Ì₤ÿ¥Í ð¡¤ÍÛÂÌñÓ¨₤ÓcacheÍÍÝÓ¤ÏÓDNSÓ°£Ó£ÿ¥Í°ð¡ÍÍÝÓ¤ÏÓDNSÍ₤Ò§Ó¥ÍÙÓIPð¡ÍÌÓ¡Íÿ¥ÍÒÏDNSÓ¡Í °ÌÌÀÈÿ¥ÿ¥ÍƒÍÛ¿ÌÍ₤¥ÒÇserverð¿ÕÇÓÒÇÒ§§ð¡ÍÒÀÀÿ¥ð¡Ò§ÍÛӯʹÌÒÇÒ§§ÍÒÀÀÿ¥Òð¡ð¡ÍÛ¿ÌÍÊÓÍ°¯Í¥ÒÇÒ§§ÐÍ´DNSÌÍÀÍ´ð¡ÿ¥ÕÌˋÍÕÓTTLÍ¥ð¿ÍƒÍ¯Õƒÿ¥Í¥Íʈͯͯð¥ÍÂÍ DNSÓÌçÕÍÒÇÒ§§ÿ¥DNSÌÍÀÍ´ð¥Ìð¡¤ÓÑÕÂÿ¥ÒƒÍÊÏÓͥͯð¥ð§¢Ó´Í´ÌÍÒÀÀÌÏÍ̓ÌÇÍñÛÐÍ°ð§¢TTLÒÛƒÓ§Ûð¡¤0ÿ¥Ò¯Í¤ÎÓÓýͤÎð¿Í hostð¡Íÿ¥ð¡ÍÓÓ´ÌñÒÛ¢ÕÛÌ´ÀÍ¥ð¿ð¥Í₤¥ÒÇÒÇÒ§§ð¡Í¿°ÒÀÀÿ¥Í ð¡¤Ìð¤Ó´ÌñÍ₤Ò§ÒÛ¢ÕÛÍÊÏÕÓÓ¨Ó¿Í ÍÛ¿ÿ¥Ìð¤Ó´ÌñÍ₤ҧ͈ÒÛ¢ÕÛ҃ͯÓÕÀçÕÂÐÕÒÎÓÌ₤ÿ¥ÍÛð¿ð¡Í₤Õ ÿ¥Í§ÌÍÀÍ´ÍÊÝÌÿ¥ÍṲ̂ÿ¥ÿ¥ÕÈð¿Ì ͯͯÌÙÊServer IPð¡ÓÍÛÂÌñÓ¨₤ͯð¡Ò§ÒÛ¢ÕÛÿ¥ÌÕ¢TTLÌÑÕÇÍ ÿ¥ÿ¥Í°ð§¢ð£ð£˜Í´ÌçÒÏð¡ð§¢Ó´ãrefreshãÐãreloadãÌð§Ð
ô
ô ô 2ÿ¥Í¤ð¤ÒÇÒ§§ÍÒÀÀÕÓƒÊÓÍÍÍ´
ô ô Dispatcherÿ¥ÍÍÍ´ÿ¥ÿ¥Í°ÒÇÒ§§ÍÒÀÀÍ´ÿ¥Í₤ð£ËͯÒ₤ñÌÝÍÍÓ£ÕÓƒÊð¡Ùð¡ÍÓserverÿ¥Ìð£ËÕÓƒÊð¡ÙÍ¿ÑÒÀÓÌÍÀÿ¥Í₤¿ÍÛÂÌñÓ¨₤ÒÒ´ÿ¥ÓÒçñÌËÍÌ₤Ò¢ÒÀÍ´ð¡ð¡ˆIPð¡ÓÒÌÌÍÀÿ¥Ó£Ó¨₤Ó´Ìñ͈ÕÒÎð¡Íð¡ˆserverð¤Êð¤Òð¡ÕÒÎÓËÕÌÇð¡ˆÕÓƒÊÓÌÌServersÐÍDNSÒÇÒ§§ÍÒÀÀÓ¡Ì₤ÿ¥DispatcherÒ§ÍÊÓ£ÕÂÓýͤÎÓүͤÎÒ₤ñÌÝÿ¥Ì₤ÍÎÌ ¿ÌÛconnectionÿ¥ÌÇÍ˧ʹserversð¿ÕÇÍÛÓ¯ÒÇÒ§§ÍÒÀÀÐͧreal serverÍÊÝÌÌÑÍÛÒÂ¨Ì ÒÛ¯ð¡¤ãÍÊÝÌãÿ¥serverÓÛÀÓð¿ÕÍ¡¡ÓÛÍÿ¥ÓÛÀÓÍÍ₤ð£ËÍ´ð££ð§ÌÑÍÍÂÐÍserverÿ¥Òð¡ÕÒÎÌÌÙÓ£Ó¨₤Ó´ÌñÍ₤¿ÌÍÀÓð§¢Ó´Ð
ô
ô ô ÒÇÒ§§ÍÒÀÀÍ₤ð£ËÍ´2ð¡ˆÍÝÕÂÌËÍÿ¥Í¤Ó´ÍÝÿ¥Application-Levelÿ¥ÍIPÍÝÿ¥IP-Levelÿ¥ÐÌ₤ÍÎãReverse-ProxyãÍãpWEBãÌ₤ͤӴÍÝÓÒÇÒ§§ÍÒÀÀÍ´ÿ¥Ó´ÌËÌÌÑÌˋÍÝÌÏÓwebÌÍÀÍ´ÕÓƒÊÿ¥ÍÛð£˜Í¯HTTPÒ₤ñÌÝÒ§˜ÍÓ£ÕÓƒÊð¡Ùð¡ÍÓwebÌÍÀÍ´ÿ¥ÒñÍÍͤÿ¥Í¿ÑÒ¢ÍÓ£ÍÛÂÌñÓ¨₤ÿ¥Í ð¡¤Í´Í¤Ó´ÍÝÿ¥HTTPÒ₤ñÌÝÓÍÊÓÍͤÓÙÌ₤Õ¨ÒÓÿ¥ÕÈð¿Í§ÕÓƒÊð¡ÙÌÍÀÍ´Ó̯ÕÍÂÍ Í¯5ð¡ˆÌÒ ÌÇÍÊÿ¥Ò¢ÓÏͤӴÍÝÒÇÒ§§ÍÒÀÀÍ´ð¿ð¥Ìð¡¤ÓÑÕÂÿ¥Ò¢ðƒÒçð¤Ì₤ð¡ˆserverÓÍÍÒ§ÍÐ
ô
ô ô Ìð£˜ÌÇ̓Íð¤IPÍÝÓÒÇÒ§§ÍÒÀÀÿ¥Í ð¡¤ÍÛÓÌÏÒ§ÌÑÒ҃ͯÿ¥Í₤ð£ËÌ¢Ò§§ÍÊÒƒƒ25ÓÒ°100ð¡ˆserverÓÒÇÒ§§ÍÒÀÀÐÒ¢ð¿Ì₤IPÒÌÌÍÀÍ´ÓÒÛƒÒÛÀÓÛÓÐLVSÓÌ ¡Í¢Í¯ÝÌ₤IPÍÝÓÒÇÒ§§ÍÒÀÀÐ
ô
ð¤ÐÒÌÌÍÀÍ´Ì₤ÍÎð§Ò¢ð§Óÿ¥
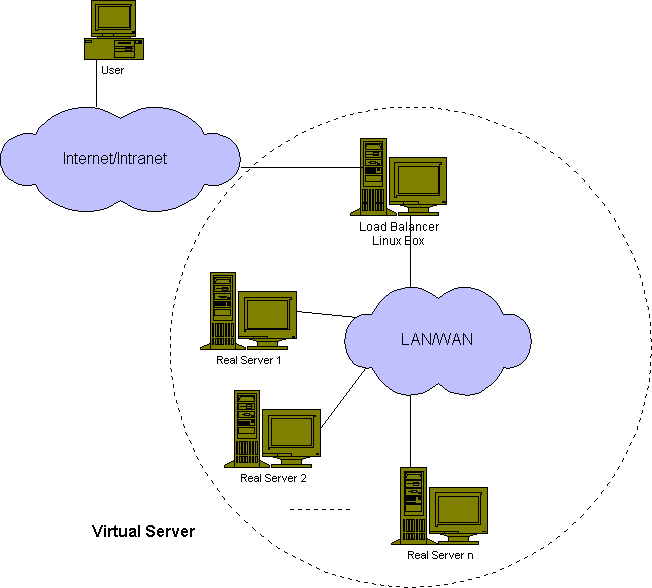
ô ô ÓÛÍð¡¤ÌÙÂÿ¥ÒÌÌÍÀÍ´ÿ¥Virtual Serverÿ¥Ìð¡ÓÏÍÛӯ̿ͥÿ¥Ò¢ð¡ÓÏIPÒÇÒ§§ÍÒÀÀÌÌ₤ÍÌÑÍÙÍ´ð¤LinuxDirectorð¡Ùÿ¥NATÿ¥IP Tunnelingÿ¥Direct routingÐð¡Ìð¡ÙãÒÌÌÍÀÍ´ãð¡¤ãVirtual Serverãÿ¥LVSÿ¥ÿ¥ÒÇÒ§§ÍÒÀÀÍ´ð¡¤ãload balancerãÿ¥ÒÌÌÍÀÍ´Í ñÌãÒÇÒ§§ÍÒÀÀÍ´ãÓ£ð£ÑÐ
ô

ô ô 1ÐNAT
ô ô NATÓð¥Ó¿Ì₤real serverÍ₤ð£Ëð§¢Ó´ð££ð§Ìð§Ó°£Ó£ÿ¥linuxÿ¥Mac OSÿ¥windowsÓÙÿ¥ÿ¥ÍˆÒÎÍÛÒ§ÍÊÌ₤ÌTCP/IPÍÒÛÛÍ°Í₤ÿ¥real serversÒ§ÍÊð§¢Ó´ÓÏÌӧӣͯÍÿ¥privateÓ§Ó£ÿ¥ÿ¥ÍˆÕÒÎÓ£ÒÇÒ§§ÍÒÀÀserverð¡ð¡ˆÍÊÓ§IPÍ°Í₤Ð
ô ô Ó¥¤Ó¿Ì₤ÿ¥NATÌ´ÀÍ¥ð¡ÿ¥ÒÌÌÍÀÍ´ÓÌˋÍÝÒ§ÍÌÕÿ¥Í§ÕÓƒÊð¡ÙserverÓ̯ÕÍÂբͯ20ÌÒ ÌÇÍÊÌÑÿ¥ÒÇÒ§§ÍÒÀÀʹͯÌð¡¤ÌÇð¡ˆÓ°£Ó£ÓÓÑÕÂÿ¥Í ð¡¤Ò₤ñÌÝ̯ÌÛÍ ÍÍ̯ͤÌÛÍ Õ§ÕÒÎÕÒ¢ÒÇÒ§§ÍÒÀÀÍ´ÓÕÍÿ¥rewrittenÿ¥ÐÍÒÛƒÿ¥TCPÓ̯ÌÛÍ ÓÍÊÏͯð¡¤536ÍÙÒÿ¥ÕÍ̯ÌÛÍ ÒÌÑ60usÿ¥ÍƒÛÓÏÿ¥Óƒð¡Íð¿ð¡ÓÏÿ¥ÿ¥ÒÇÒ§§ÍÒÀÀÍ´ÌÍÊÏÓÍÍÕð¡¤8.93M/sÿ¥ÍÎÌreal serverÓÍÍÒ§Íð¡¤400KB/sÿ¥ÕÈð¿ÒÇÒ§§ÍÒÀÀÍ´Ò§ÍÊүͤÎ22ð¡ˆreal serverÐ
ô
ô ô ÕÒ¢NATÍÛÓ¯ÓÒÌÌÍÀÍ´Ò§ÍÊÌ£ÀÒÑ°ÍÊÏÕÍÛÂÌñÓ¨₤ÓÒ₤ñÌÝÿ¥Í§ÒÇÒ§§ÍÒÀÀÍ´Ìð¡¤ÌÇð¡ˆÓ°£Ó£ÓÓÑÕÂÌÑÿ¥Ì2ÓÏÕ̓Í₤ð£ËÒÏÈÍ°Ò¢ð¡ˆÕÛÕÂÐð¡ð¡ˆÌ₤ÌññÍÕ̓ÿ¥hybridÿ¥ÿ¥ÍÎð¡ÓÏÍÌ₤ð§¢Ó´IP tunnelingÌÒ Direct routingÐÍ´DNSÌññÍÕ̓ð¡Ùÿ¥ÌÍÊð¡ˆÍ¤ð¤NATÓÕÓƒÊÓ₤ÍÂÿ¥ÍÍÌ Í¯Í¯ÍÊð¡ˆÒÌÌÍÀÍ´ÓIPÐÌð£˜Í₤ð£Ëð§¢Ó´LVSð¡ÙÓãIP TunnelingãÐãDirect RoutingãÌÕ¨ÌˋÍÝÌÏÿ¥ð¿Í₤ð£ËÍ´Ó˜˜ð¡Ó¤Ïð§¢Ó´ãIP TunnelingãÌÒ ãDirect RoutingãÒÇÒ§§ÍÒÀÀÍ´ÿ¥ÓÑÍÍ´Ó˜˜ð¤Ó¤Ïð§¢Ó´NATÌ´ÀÍ¥ÿ¥ð£ËÌÍ£¤ÍÊÏÒÏÌ´ÀÓÕÓƒÊÐÿ¥LVS DR + nginxͯÝÌ₤Ò¢ÓÏÌ´ÀÍ¥ÿ¥
ô
ô ô NATÌ´ÀÍ¥ÿ¥Ò¢ÍnginxÓÒÇÒ§§ÍÒÀÀÌ´ÀÍ¥ÕÍ¡¡Ó¡ð¥¥Ð
ô
ô ô 2ÐIP Tunneling
ô ô Ìð£˜ÍñýÓ£ð¤ÒÏÈͯÿ¥NATÌ´ÀͥͥӨ₤Í´ð¤Ò₤ñÌÝÍÍͤէÕÒÎÓ£Ò¢ÒÇÒ§§ÍÒÀÀÍ´ÿ¥Ò¢ÕÍÑð¤ÕÓƒÊÓÒÏÌ´ÀÓÌˋÍÝÐÍ₤¿ð¤ÍÊÏÍÊ̯webͤӴÿ¥Ò₤ñÌÝÓ̯ÌÛÍ ÒƒÍ¯ÿ¥ÍͤÓ̯ÌÛÍ ÒƒÍÊÏÐ
ô ô IP TunnelingÌ´ÀÍ¥ÓÒÌÌÍÀÍ´ÿ¥ÒÇÒ§§ÍÒÀÀʹ͈ÕÒÎͯÒ₤ñÌÝÍÍÓ£ð¡ÍÓreal serverÿ¥real serverÓÇÌËͯÍͤҢÍÓ£ÍÛÂÌñÓ¨₤ÐÌð£Ëÿ¥ÒÇÒ§§ÍÒÀÀÍ´Ò§ÍÊÍÊÓÌçñÕÓÒ₤ñÌÝÿ¥ÍÛÒ§ÍÊүͤÎÕ¨Òƒƒ100ð¡ˆreal serverÿ¥Í¿Ñð¡ÍÛð¡ð¥Ìð¡¤Ó°£Ó£ÓÓÑÕÂÐTunnelingÓÍÍÒ§ÍÕ¨Òƒƒ1GBÿ¥ÒÒÇÒ§§ÍÒÀÀʹ͈Ì100MÓÍ ´ÍÍñËÓ§Ó£ÕÕ Í´Ð
ô
ô ô ÓÝÌÙÊÍ₤ÒÏÿ¥IP TunnelingÓ¿ÌÏÍ₤ð£ËÓ´ÌËÌÍ£¤ÌÏÒ§ÌÕ¨ÓÒÌÌÍÀÍ´ÿ¥ÕÍ¡¡ÕÍÌÍ£¤ÒÌð£ÈÓÌÍÀÍ´ÿ¥Í ð¡¤Í§ð£ÈÓÌÍÀÍ´ÌÑͯÒ₤ñÌÝÍÿ¥ÍÛÍ₤ð£ËÓÇÌËÒÛ¢ÕÛÓ§Ó£ÿ¥ÒñÍÍ ÍÛ¿ÿ¥Í¿ÑÓÇÌËÒ¢ÍÓ£Ó´ÌñÐ
ô
ô ô ð¡Ò¢ÿ¥ÌÌÓserverÕÒÎÌ₤ÌãIP TunnelingãÍÒÛÛÿ¥Í°IPͯÒÈ ÿ¥IPIPÿ¥,ÓÛÍÍñýÓËÓ͈ÌlinuxÓ°£Ó£ÍÌ₤ÌÌÙÊÓ¿ÌÏÐ
ô
ô ô 3ÐDirect Routing
ô ô ÍãIP Tunnelingãð¡Ì ñÿ¥linuxDirectorÍÊÓÓ͈Ì₤Client-ServerÓÍÕƒÌËÿ¥Í̯ͤÌÛÍ₤ð£ËÌ ¿ÌÛÍÒˆÓÓ§Ó£Òñ₤ÓÝ̿ͥͯ҃ƒÍÛÂÌñÓ¨₤ÿ¥Í°ÒÇÒ§§ÍÒÀÀÍ´ÌËÌÑÒ₤ñÌÝÿ¥Ò₤ñÌÝÒ§˜ÍÓ£real serverÿ¥ÓÑÍÍͤÓÇÌËÒ¢ÍÓ£ÍÛÂÌñÓ¨₤ÒÌ ÕÓ£Ò¢ÒÇÒ§§ÍÒÀÀÍ´ÐÍÛÍ ñÌãIP TunnelingãÓð¥Ó¿Ð
ô
ô ô ð¡Ò¢ÍãIP TunnelingãÓ¡Ì₤ÿ¥Ò¢ÓÏ̿ͥͿÑÌýÀÌãtunnelingãÓÍ¥Ì₤ÿ¥IPͯÒÈ ÿ¥Í ÑÍÛÍ¥Ì₤ÕÍ¡¡Í¯ÿ¥ÿ¥ð§Ì₤ÍÛÕÒÎÒÇÒ§§ÍÒÀÀÍ´Ó§Ó£ÌËÍÈð¡real serverÓÓ§Ó£ÌËÍÈÍ¢ ÕÀ£Í´Íð¡ð¡ˆÓˋÓÓ§ÌÛçÐ
ô ô ô
ô ô Ì ¿ÌÛð¡Ò¢¯ð£Ó£ÿ¥Ìð£˜ÓÛÍÓ̓ͯӣÒÛ¤ÿ¥ãIP TunnelingãÍãDirect RoutingãÌ´ÀÍ¥Ò§ÍÊÌÍ£¤ÒƒÍÊÏÒÏÌ´ÀÓÕÓƒÊÒÇÒ§§ÿ¥ÌˋÍÝÌÏÌ₤NATÌÇÍ¥¤ÿ¥ãNATãÓ§Ó£ÌÌÓ£ÌÓÛÍÿ¥real server͈ÕÒÎÌ₤ÌTCP/IPÍÒÛÛÍ°Í₤ÿ¥ÍÛð£˜Í₤ð£ËÍ´LANÐWANÓ§Ó£ð¡Ùÿ¥ãIP TunnelingãÕÒÎÕÓƒÊð¡ÙÓreal serverÌ₤ÌIPͯÒÈ ÍÒÛÛÿ¥real serverÍ₤ð£Ëð§ð¤LANÐWANÓ§Ó£ð¡Ùÿ¥Í´ÍÛÕ Ó₤ÍÂð¡Ùÿ¥Õ Ó§ÛӴ̓ÛÍÊÌÿ¥Ò¢ÓÏÌ´ÀÍ¥ð¡Í¡¡Ó´ÿ¥ãDirect RoutingãÌ´ÀÍ¥ÕÒÎLVSð¡real serverð§ð¤Íð¡Ó§ÌÛçÿ¥Õ Ó§ÛÓÛÍÿ¥Ì₤Ì₤҃͡¡Ó´ÓÌ¿Í¥Ð
ô
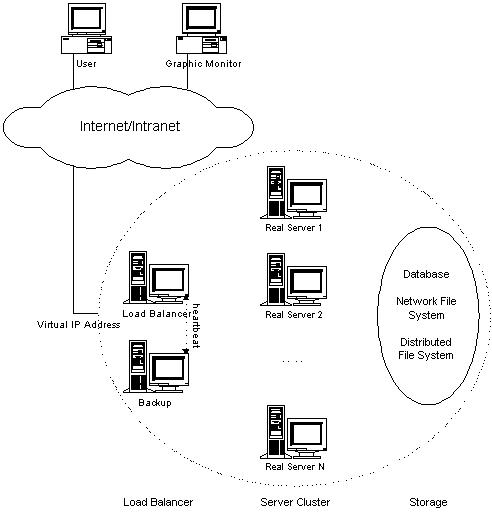
ð¡ÐLVSÕÓƒÊÌÑÌ
ô ô ð¡¤ð¤ÌÇð¡ˆÓ°£Ó£ÓÕÌͤÎÐÍ₤ÌˋÍÝÌÏÐÍ₤Ó´ÌÏð£ËÍÍ₤ÓÛÀÓÌÏÿ¥Ìð£˜ÕÍ¡¡ÕÓ´ÍÎ̓ÌÓʤÓð¡ÍÝÌÑÌÿ¥
ô
ô
ô ô ð¡ÍÝÌÑÌÌÍÎð¡Í ð¡ˆÕ´ÍÓ£Ìÿ¥
ô ô 1Ðload balancerÿ¥ÒÇÒ§§ÍÒÀÀÍ´ÿ¥ÿ¥ð§ð¤ÌÇð¡ˆÕÓƒÊÓÍÓ¨₤ÿ¥Ó´ð¤Í´ÍÊð¡ˆreal serverð¿ÕÇÍÒÀÀÌËÒˆÍÛÂÌñÓ¨₤ÓÒ₤ñÌÝ ÿ¥Í₤¿ð¤ÍÛÂÌñÓ¨₤ÒÒ´ÍÛð£˜ÒÛÊð¡¤ÌÌÓÌÍÀÍÌËÒˆð¡ð¡ˆIPͯÍÿ¥Í°load blancerÓIPͯÍÐ
ô ô 2Ðserver clusterÿ¥ÌÍÀÍ´ÕÓƒÊÿ¥ÿ¥ÌÍÊð¡ˆreal serverÓ£Ìÿ¥ÍÛð£˜ÌðƒÍÓÙÓÌÍÀÐ
ô ô 3Ðshared storageÿ¥Í Ýð¤¨ÍÙÍ´ÿ¥ÿ¥Ó´ð¤ÌðƒserversÍ Ýð¤¨ÓÍÙÍ´Óˋ¤ÕÇÿ¥Ò¢Ì₤serversÒñÍÓ¡ÍÓÍ ÍÛ¿ÐÌðƒÓ¡ÍÓÌÍÀÓͤÓÀÐ
ô
ô ô ÒÇÒ§§ÍÒÀÀÍ´Ì₤ÌÇð¡ˆÕÓƒÊÓ°£Ó£ÓÍð¡Í ËÍÈÿ¥ÍÛÍ₤ð£ËÒ¢ÒÀIPVSÿ¥linuxÍ Ì ¡ð¡Ùÿ¥ð£ËÌðƒÍ¤ð¤IPÓÒÇÒ§§ÍÒÀÀÌÌ₤ÿ¥ÌÒ Ì₤Ò¢ÒÀKTCPVSÌËÍÛӯͤӴÍÝÓÒÇÒ§§ÍÒÀÀÐͧð§¢Ó´IPVSÌÑÿ¥ÌÌÓserversÕÒÎÌðƒÓ¡ÍÓÌÍÀÍÍ ÍÛ¿ÿ¥ÒÇÒ§§ÍÒÀÀÍ´ÕÒ¢ÌÍÛÓүͤÎÓÛÌ°ÍserverÕ§ÒÇÒ§§Ì Íçÿ¥Í¯ÍÛÂÌñÓ¨₤Ò₤ñÌÝÒ§˜ÍÓ£Ìð¡ˆÍÕÓserverÐÌ ÒÛ¤ÕÌˋð¤Íˆð¡ˆserverÿ¥ÌÓ£ÓÍͤӣÌͤÒ₤ËÌ₤ð¡Ì ñÓÿ¥ÍÎÍͯÝÒ¢Òð¤ÕÓƒÊÌÍÀÓ̘ͤÍÍÿ¥Ðͧð§¢Ó´KTCPVSÌÑÿ¥serversÍ₤ð£ËÒ¢Íð¡ÍÓÍ ÍÛ¿ÿ¥ÒÇÒ§§ÍÒÀÀÍ´Í₤ð£ËÌ ¿ÌÛÒ₤ñÌÝÓÍ ÍÛ¿ÿ¥URLÿ¥Í̯ÓÙÿ¥Í¯Ò₤ñÌÝÒ§˜ÍÓ£ð¡ÍÓserverÐÍ ð¡¤KTCPVSÌ₤linuxÍ Ì ¡ÍÛÓ¯ÿ¥Ìð£ËÍÊÓ̯ÌÛÓÍ¥Ì₤҃ͯÿ¥ÌÇð¡ˆÕÓƒÊð£ÓÑÒ§ÍÊÌðƒÒƒÕ¨ÓÍÍÕÐ
ô
ô ô ÕÓƒÊð¡ÙserverÒÓ¿Ó̯ÕÍ₤ð£ËÌ ¿ÌÛÓ°£Ó£ÓÒÇÒ§§ÒÒ¯ÌÇÿ¥Í§ÌÌÓserverÕ§Ò¢Ò§§ÌÑÿ¥Ìð£˜ÕÒÎÍÕÓƒÊÍÂÍ ÍÊð¡ˆÌ¯ÓserversÌËÍÊÓÒ¢ð¤ÍÂÕ¢ÓÍñËð§ÕÐÍ₤¿ð¤ÍÊÏÍÊ̯ð¤ÒÓ§ÌÍÀÿ¥Ì₤ÍÎwebÓ¨Ó¿ÿ¥Ò₤ñÌÝð¿ÕÇÓ¡Í °ÌÏð¡Õ¨ÿ¥ÍÛð£˜Í₤ð£ËÍ´ð¡ÍÓserverð¡Í¿ÑÒÀÒ¢ÒÀÿ¥Í ÌÙÊÿ¥ÕÓÕÓƒÊð¡Ùserver̯ÕÓÍÂÍ ÿ¥ÌÇð¡ˆÓ°£Ó£ÓÌÏÒ§ð¿ð¥ÌÓ¤¢ÌÏÌˋÍÝÐ
ô
ô ô Í Ýð¤¨ÍÙÍ´ÿ¥Í₤ð£ËÌ₤̯ÌÛͤӰ£Ó£ÐÓ§Ó£Ìð£ÑÓ°£Ó£ÿ¥NFSÿ¥ÿ¥ÌÒ Ì₤ÍÍ¡Í¥Ìð£ÑÓ°£Ó£ÿ¥DFSÿ¥;ÕÒÎserverÒÓ¿Í´ÌÌÇ̯Ó̯ÌÛÕÒÎÒ¨ð¢ÍÙʹ̯ÌÛͤð¡Ùÿ¥Í§ÍÊð¡ˆserverÒÓ¿Í¿ÑÒÀÒ₤£Í̯ÌÛͤӰ£Ó£ÌÑÿ¥Ì¯ÌÛͤÕÒÎð¢Ò₤̯ÌÛÓð¡ÒÇÌÏÿ¥Í¿ÑÍÌð§ÿ¥ÿ¥Í₤¿ð¤ÕÌ̯ÌÛÿ¥ÕÍ¡¡Í₤ð£Ëð¢ÍÙÍ´Ìð£ÑÓ°£Ó£ð¡Ùÿ¥Ì₤ÍÎNFSÿ¥Ò¢ð¤Ì¯ÌÛÍ₤ð£ËÒ¨ÌÌÓserverÒÓ¿Í Ýð¤¨Ðð§Ì₤Íð¡ˆNFSÓ°£Ó£ÌˋÍÝÌÏÌ₤ÌÕÍÑÓÿ¥ð¡ð¡ˆNFS͈ҧÌ₤Ì4~8ð¡ˆserverÒÓ¿ÓÒÛ¢ÕÛÿ¥Í₤¿ð¤ÌÇÍÊÏÒÏÌ´ÀÓÓ°£Ó£ÿ¥ÕÍ¡¡ð§¢Ó´ÍÍ¡Í¥Ìð£ÑÓ°£Ó£ÿ¥Ì₤ÍÎGFSÿ¥Ò¢Ì ñÍ Ýð¤¨ÍÙÍ´Ó°£Ó£Í₤ð£ËÌ ¿ÌÛÕÒÎÒ¢ÒÀÒÏÌ´ÀÌˋÍÝÐ
ô ô ÒÇÒ§§ÍÒÀÀÍ´ÐÌÍÀÍ´ÕÓƒÊÐÍ Ýð¤¨ÍÙÍ´Ó°£Ó£ÿ¥Ò¢ð¡Ò ð¿ÕÇÕÍ¡¡ð§¢Ó´Õ¨ÕÓÓ§Ó£ÕƒÌËÿ¥Ì₤ÍÎ100MÍGBð£ËÍʈӧӧӣÿ¥Ìð£ËͧӰ£Ó£ð¡ÌÙÍÂÕ¢ÌÑÓ§Ó£ð¡ð¥Ìð¡¤ÍÛð£˜ð¿ÕÇÓÓÑÕÂÐ
ô
ÍÐÕ¨Í₤Ó´ÌÏ
ô ô ÒÑÌËÒÑÍÊÓÕÒÎͤӴҢÓϣͯð¤ÒÓ§ð¡ÿ¥ÕÈð¿ÌðƒÕ¨Í₤Ó´ÓÌÍÀͯÍ̓ÕÍ¡¡ÕÒÎÐÕÓƒÊÓ°£Ó£Óð¥Í¢ð¿ð¡Í¯ÝÌ₤Ò§₤ÓÀ˜ð£ÑÓÍð§ÌÏÿ¥Í ð¡¤ÕÓƒÊÓ°£Ó£ÌÍÊð¡ˆÓ˜Ó¨ÓÒÓ¿ÌÌÿ¥Í¿Ñð¡Ì₤ð¡ˆÒÓ¿Õ§Ò¢ÒÀÓ¡ÍÓͤӴӰ£Ó£ÿ¥Õ¨Í₤Ó´ÌÏÍ₤ð£ËÕÒ¢ÓÏ£ÕÊÍÊÝÌÒÓ¿ÍÕͧÕÌ¯Õ Ó§ÛÕÓƒÊÓ°£Ó£ÓÌÌÛçÍÛÓ¯ÿ¥ÕÓƒÊð¡ÙÍˋð§ÓÒÓ¿Í°Í₤ÌËÓÛÀÍÊÝÌÒÓ¿ð¡ÓÍñËð§ÕÐ
ô ô Í ÑÍÛãÕ¨Í₤Ó´ÌÏãÌ₤ð¡ð¡ˆÒƒÍÊÏÓÕÂÍÿ¥ð¡ð¡ˆÍ Ò¢ÓÕ¨Í₤Ó´Ó°£Ó£ð¥Í ͨÍ₤Õ ÓãÓ£ÕÒÛ₤ÍÙÓ°£Ó£ãÐãÌÍÓÛÀÓãÐãquoramÍÙÓ°£Ó£ãÐãÍ¿ÑÍÌÏÍÑÍÙÓ°£Ó£ãÓÙÓÙÐÍ Ñð¡ÙÍ¢ Ì̓ÍÊð¤Ì ÕÒÎÒÏÈÍ°ÿ¥ð¡Ò¢ÿ¥Ìð£˜Í₤ð£Ëð§¢Ó´Ó¯ÌÓÒ§₤ð£ÑÍ ÌËÌÍ£¤Õ¨Í₤Ó´ÓLVSÕÓƒÊÓ°£Ó£Ð
ô
ô ô ÍñËð§ÍÓÿ¥
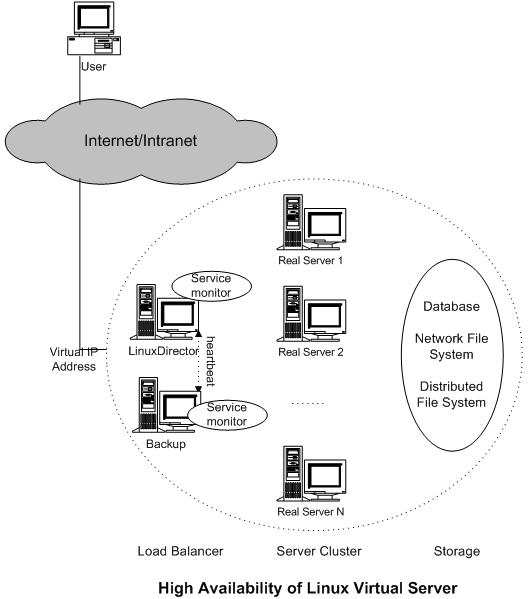
ô ô ÕÍ¡¡Ì Íçð¡ÿ¥ÒÇÒ§§ÍÒÀÀÍ´ð¥Ò¢ÒÀð¡ð¡ˆÓÌÏÌÍÀÌËÕÇÌÙÌÏÓÌÈÌçserverÓÍËͤñÓÑÍçÿ¥ÍÎð¡ÍƒÌÓʤÐÍÎÌÍ₤¿serverÓÌÍÀÒÛ¢ÕÛÒ₤ñÌÝÌÒ ICMPÿ¥pingÿ¥ÌýÀÌÌÑͯÍͤÿ¥ÕÈð¿ÌÍÀÓÌÏÿ¥monitorÿ¥Í¯ð¥ÒÛÊð¡¤ÌÙÊserverÍñýÓ£ãdeadãÿ¥Í¿Ñð£Í₤Ó´serverÍÒÀ´ð¡ÙÓÏ£ÕÊÿ¥ÌÙÊÍͯð¡ð¥ÌÒ₤ñÌÝÒ¨ҧ˜ÍͯÌÙÊserverð¡ÐͧmonitorÌÈÌçͯÍÊÝÌÓserverÌÂÍÊÌÙÈÍ¡¡ÿ¥ÕÈð¿Í¯ÌÙÊserverÕ̯Ìñ£Í ͯÍ₤Ó´serverÍÒÀ´ð¡Ùÿ¥Í ÌÙÊÒÇÒ§§ÍÒÀÀÍ´Í₤ð£ËÒˆÍ´Ì ÒÛ¯ÍÊÝÌÓserverÐͧÓÑÿ¥ÓÛÀÓÍð¿Í₤ð£Ëð§¢Ó´Ó°£Ó£ÍñËÍ ñÌËÍÂÍserverÿ¥ð£ËÓ£ÇÌÊÕÓƒÊÓ°£Ó£ÿ¥ÒÌ ÕÍ °ÕÙÌÇð¡ˆÕÓƒÊÌÍÀÐ
ô
ô ô ô ð¡Ò¢ÒÇÒ§§ÍÒÀÀÍ´ÌÒÛ¡Ìð¡¤ÌÇð¡ˆÓ°£Ó£ÓÍÓ¿ÕÛÕÂÿ¥ð¡¤ð¤Õ¢Í Í ð¡¤ÒÇÒ§§ÍÒÀÀÍ´ÓÍÊÝÌÒÍ₤¥ÒÇÌÇð¡ˆÕÓƒÊÌÍÀð¡Í₤Ó´ÿ¥Ìð£˜ÕÒÎÍ₤¿ÒÇÒ§§ÍÒÀÀÍ´ÍÂÍ backupÿ¥ð¡ð¡ˆÌÍÊð¡ˆÿ¥Ðð¡Êð¡ˆheartbeatÍÛÌÊÒ¢Ó´ÍͨҢÒÀÍ´primaryÍbackupÒÓ¿ÿ¥ÍÛð£˜ÕÇÌÙÌÏÓð¤Ó¡ÍÕÍ¢Òñ°ÌÑÌ₤ÿ¥ÍÎÌbackupÓÍ¢Òñ°Ò¢Ó´Í´ð¡ÌÛçÌÑÕÇÍ Ì Ì°ÌÑͯÌËÒˆÿ¥ÍÕÿ¥primaryÒÓ¿ÓÍ¢Òñ°ÌÑÌ₤ÿ¥ÍÛͯÌËÓÛÀÌðƒÒÇÒ§§ÍÒÀÀÌÍÀÓVIPͯÍÿ¥Í§ÕÈð¡ˆÍÊÝÌÓÒÇÒ§§ÍÒÀÀÍ´ÌÂÍÊÍñËð§ÿ¥ÌÙÊÌÑð¥Ì2ÓÏÌ Íçÿ¥ð¡Ì₤ÍÛÌð¡¤backupÿ¥ÍÎð¡ÓÏÌ ÍçÍÌ₤ͧÍactiveÓÒÇÒ§§ÍÒÀÀÍ´Õ̃VIPÿ¥ÍÛÌËÓÛÀVIPÍ¿ÑÓ£ÏÓ£ÙÌð¡¤primaryÐ
ô
ô ô primaryÒÇÒ§§ÍÒÀÀÍ´ÌÌÕƒÌËÓÓÑÌÿ¥Í°ÍÛÂÌñÓ¨₤ÕƒÌËÒ¨ҧ˜Í͈ͯð¡ˆserverð¡ÿ¥ÍÎÌbackupÌËÓÛÀVIPÍÿ¥Í Ñð¡ÌýÀÌÒ¢ð¤ÕƒÌËÓÑÌÓð¢ÀÌ₤ÿ¥ÍÛÂÌñÓ¨₤ÕÒÎÕ̯Ò₤ñÌÝÐð¡¤ð¤ÒÛˋÒÇÒ§§ÍÒÀÀÍ´ÓÌ ÕÒ§˜ÓÏ£Í₤¿ÍÛÂÌñÓ¨₤ͤӴÕÌÿ¥Ìð£˜Í´IPVSð¡ÙÍÛÓ¯ð¤ÕƒÌËÍÌÙËÿ¥primary IPVSͯð¥ÌÕƒÌËÓÑÌð¢ÀÌ₤ÕÒ¢UDPÍÊÌÙÌ¿Í¥ÍÌÙËÓ£backupÐͧbackupÒÇÒ§§ÍÒÀÀÍ´ÌËÓÛÀÍÿ¥Í Ñð¡ÍñýÓ£ÌÌð¤Ó£ÍÊÏÍÊ̯ՃÌËÓÑÌð¢ÀÌ₤ÿ¥Ìð£ËÍ ð¿ÌÌÓÕƒÌËͯÍ₤ð£ËÓ£ÏÓ£ÙÕÒ¢backupÒÇÒ§§ÍÒÀÀÍ´ÒÛ¢ÕÛÌÍÀÐÿ¥ÍÊÌ°´ÿ¥Ò₤ñÍÓkeepalivedÓ¡Í °ÌÌ₤ÌÌÀÈÿ¥
ô
ð¤ÐNATÌ´ÀÍ¥
ô ô Í§Í ð¤IPv4ͯÍÓÓÙÓ¥¤ÌÒ ð¡ð¤ÍÛÍ ´ÍÍ ÿ¥ÒÑÌËÒÑÍÊÓÓ§Ó£ð§¢Ó´ð¡ð¤ÍÝÍӧͯÍÿ¥Ì₤ÍÎÿ¥ð£Ëã10ãÐã198ãÐã172ãÍ¥ÍÊÇÓIPͯÍÿ¥Ò¢ð¤Í¯ÍÌ Ì°Í´ð¤ÒÓ§ð¡ð§¢Ó´ÐÍÎÌÒ¢ð¤Í մӧӣͯÍÕÒÎÒÛ¢ÕÛð¤ÒÓ§ÿ¥ÌÒ Ò¨ð¤ÒÓ§ÒÛ¢ÕÛÿ¥ÍÕÒÎӧӣͯÍÒ§˜ÌÂÿ¥ÍÓÍ´Òñ₤ÓÝÍ´ð¡ÿ¥Ðÿ¥Í°NATÌ´ÀÍ¥ð¡ÿ¥ÍˆÕÒÎÒÇÒ§§ÍÒÀÀÍ´ÌÍÛÕ ÍÊÓ§IPÍ°Í₤ÿ¥ÍÌÑÕÒÎð¡ð¡ˆÍÊÓ§ÓVIPÿ¥Í₤¿ð¤real serverÍð§¢Ó´Í Ó§IPÿ¥
ô ô ӧӣͯÍÒ§˜ÌÂÌ₤ͯð¡Ó£IPͯÍÌ Í¯Í¯ÍÎð¡Ó£ð¡ÐͧͯÍÌ Í¯Ì₤NͯNÿ¥ÿ¥Í°ð¡Í₤¿ð¡ÿ¥ÿ¥Ìð£˜Ìð¡¤ÕÌӧӣͯÍÒ§˜ÌÂÿ¥ÍÎÌÌ₤MͯNÿ¥M > Nÿ¥ÿ¥Ò¢ÓÏÌ ÍçÓϯð¿ð¡¤Í´ÌӧӣͯÍÒ§˜ÌÂÐÍ Ñð¡ÙN-1ÓÒ¢ÓÏmappingÿ¥ð§¢Ó´linux IPð¥ˆÒÈ ÍÛÓ¯Ð
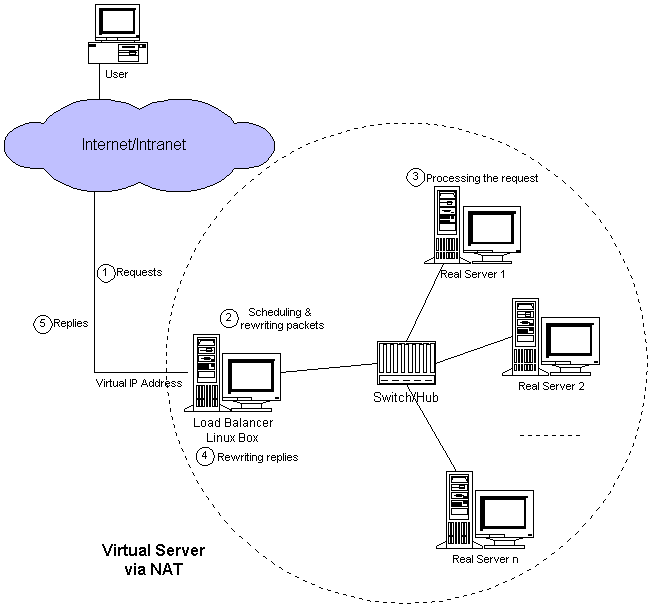
ô ô ͧӴÌñÒÛ¢ÕÛÕÓƒÊÌÍÀÌÑÿ¥Ò₤ñÌÝ̯ÌÛÍ Í̓VIPͯÍÿ¥ÒÇÒ§§ÍÒÀÀÍ´ÓͯÍÿ¥ÓÒÇÒ§§ÍÒÀÀÍ´ÿ¥ÒÇÒ§§ÍÒÀÀÍ´ÌÈÌç̯ÌÛÍ ÓͯÍÍÓ¨₤ÍÈÍñÿ¥Ì ¿ÌÛÒÌÌÍÀÍ´ÒÏÍÒÀ´ÿ¥ÍÎÌÍÛð£˜ð¡ÒÌÌÍÀÍ´ð¡ÓÌÍÀÍ¿Õ ÿ¥Õ Ó§ÛÌð£ÑÍ°ÍÛÿ¥ÿ¥ÕÈð¿Í¯ð¥Ì ¿ÌÛүͤÎÓÛÌ°ð£ÕÓƒÊð¡ÙÕÌˋð¡ð¡ˆreal serverÿ¥ÌÙÊÕƒÌËͯð¥Ò¨Ìñ£Í ͯð¡ð¡ˆhashtableð¡ÿ¥ÌÙÊhashtableÒۯͧð¤ÕÈð¤Íñýӣͣ¤Ó¨ÓÕƒÌËÐÓÑÍ̯ÌÛÍ ÓÓÛÌ Í¯ÍÍÓ¨₤ÍÈͯð¥Ò¨ÕÍð¡¤Í§ÍÕÌˋÓreal serverÿ¥Í¿Ñð¡Ì¯ÌÛÍ Í¯ð¥ÓÝÒÇÒ§§ÍÒÀÀÍ´Ò§˜Ó£Ò¨ÕÌˋÓreal serverÐÌÙÊÍÿ¥ÌËÒˆÌÙÊÕƒÌËÓ̯ÌÛÍ ÿ¥packageÿ¥ð¡Ò¨ÕÌˋÓreal serverÒ§ÍÊÍ´hashtableð¡Ù̃ͯÿ¥ÕÈð¿Ì¯ÌÛÍ Í¯Ó£ÏÓ£ÙÒ¨ÕÍÍ¿ÑÒ§˜ÍͯÌÙÊreal serverð¡ÐͧͤÓÙÓ̯ÌÛÍ Ò¢ÍÌÑÿ¥ÒÇÒ§§ÍÒÀÀʹ̯ͯÌÛÍ ð¡ÙÓ̤ͯÍÍÓ¨₤ÍÈÕÍð¡¤ÒÌÌÍÀÓͯÍÍÓ¨₤ÍÈÿ¥LVSÿ¥Í¿ÑÒ¢ÍÓ£ÍÛÂÌñÓ¨₤ÐͧՃÌËð¡ÙÌÙÌÒ ÒÑ ÌÑÿ¥ÕƒÌËÒۯͧͯð¥ð£hashtableð¡ÙÍ ÕÊÐ
ô
ô ô ÌÒÛ¡Ì₤ÒƒÒ¢ñÌÿ¥ÕÈð¿Ìð£˜Ó̓ÌÓʤÐ
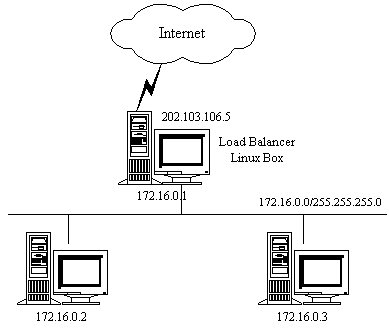
ô ô real serverÍ₤ð£ËÒ¢ÒÀð££ð§ð££ð§OSÿ¥ÍˆÕÒÎÌ₤ÌTCP/UDPÍ°Í₤ÿ¥real serversÓÕ£ÒÛÊÒñ₤̓͢ ÕÀ£ÌÑÒÌÌÍÀÍ´ÿ¥172.16.0.1ÿ¥ÿ¥ipwadmÍñËÍ ñÍ₤ð£ËÒÛˋÒÌserverÌËÌÑÌËÒˆreal serverÓ̯ÌÛÍ Ð
ô 
ô ô ô ÌÌÒÛ¢ÕÛÓÓÛÌ Í¯Íð¡¤ã202.103.106.5ãÓ¨₤ÍÈð¡¤80ÓÌçÕÕ§ð¥Ò¨ÒÇÒ§§ÍÒÀÀÍ´Ò§˜ÍÓ£ã172.16.0.2:80ãÍã172.16.0.3:8000ãÐ̯ÌÛÍ
ÕÍÓÌ¿Í¥ÍÎð¡ÌÓʤÿ¥
ô ô ô
#Ò₤ñÌÝwebÌÍÀÓ̯ÌÛÍ Í Í¨Ì¤Í¯ÍÍÓÛÌ Í¯Íÿ¥Í Ñð¡Ṳ̀ͯÍð¡¤ÍÛÂÌñÓ¨₤ͯÍÿ¥ÓÛÌ Í¯Íð¡¤ÒÇÒ§§ÍÒÀÀÍ´ÓVIPÍ¯Í SOURCE 202.100.1.2:3456 DEST 202.103.106.5:80 #ÒÇÒ§§Í̓ҧ£Í¯ð¥ÕÌˋð¡ð¡ˆreal serverÿ¥Ì₤ÍÎ172.16.0.3:8000ÿ¥Ì¯ÌÛÍ Í¯ð¥Ò¨ÕÍÍ¿ÑÒ§˜ÍͯÌÙÊserverÿ¥ SOURCE 202.100.1.2.3456 DEST 172.16.0.3:8000 #ÍͤÓ̯ÌÛÍ Í¯ÒƒƒÒÇÒ§§ÍÒÀÀÍ´ SOURCE 172.16.0.3:8000 DEST 202.100.1.2:3456 #ÒÇÒ§§ÍÒÀÀʹͯð¥ÕÍÍÍ¤Í ÿ¥Í¿ÑÒ¢ÍÓ£ÍÛÂÌñÓ¨₤ SOURCE 202.103.106.5:80 DEST 202.100.1.2:3456
ô
ô ô Í °ð¤NATÌ´ÀÍ¥ÓLVSÕ Ó§Ûÿ¥Ò₤ñÍÒÏÍÛÓ§Ð
ô
Í ÙÐIP TunnelingÌ´ÀÍ¥
ô ô Í₤¿ð¤Í¯ÍÓÒÇÒ§§ÍÒÀÀÌÑÌÿ¥Ìð£˜ÕÓ´NATÌ´ÀͥͰÍ₤Ì£ÀÒÑ°ÒÛƒÒÛÀÒÎÌÝÐÕÈð¿Í§ÕÓƒÊÌˋÍÝͯÒÑ°ÍÊÍÊÏÌÑÿ¥NATÌ´ÀÍ¥ð¡ÒÇÒ§§ÍÒÀÀʹͯÌð¡¤ÓÑÕÂÿ¥ÌÍÊÏÓÍÍ Í¯ÝÌ₤ÍͤÓ̯ÌÛð¿Í¢ ÕÀ£ÌÒÇÒ§§ÍÒÀÀÍ´ÕÍÍÒ§˜ÍÓ£ÍÛÂÌñÓ¨₤ÐIP TunnelingÒ§ÍÊÒÏÕ¢Ò¢ð¡ˆÕÛÕÂÐ
ô ô IP TunnelingÍ°IPͯÒÈ ÿ¥IPIPÍÒÛÛÿ¥ÿ¥ÍÛͯIPÌËÌÕ̯ͯÒÈ ÌÍÎð¡ð¡ˆIPÌËÌÓÌÌ₤ÿ¥Ò¢Í¯ÝÍ ÒۡͯÍ̓ð¡ð¡ˆIPͯÍÓÌËÌ̯ÌÛÕÌ¯Í ÒÈ Í¿ÑÕÍÛÍͯÍÎð¡ð¡ˆIPͯÍÐIPͯÒÈ ÌÌ₤ÓÛÍÍ¡¡Ó´Í´ãExtranetãÿ¥ÍÊÒÓ§ÿ¥ÐMobile-IPÐIP-MulticastÓÙÐÍ ñð§Ò₤ñÍÒÏÓ¡Í °ÌÌÀÈÐ
ô ô ÍÛÍNATÌ´ÀÍ¥ÌÍÊÏÓð¡ÍͯÝÌ₤ÒÇÒ§§ÍÒÀÀÍ´ÕÒ¢IP Tunneling̿ͥͯÒ₤ñÌÝÍÕÓ£real serverÐ
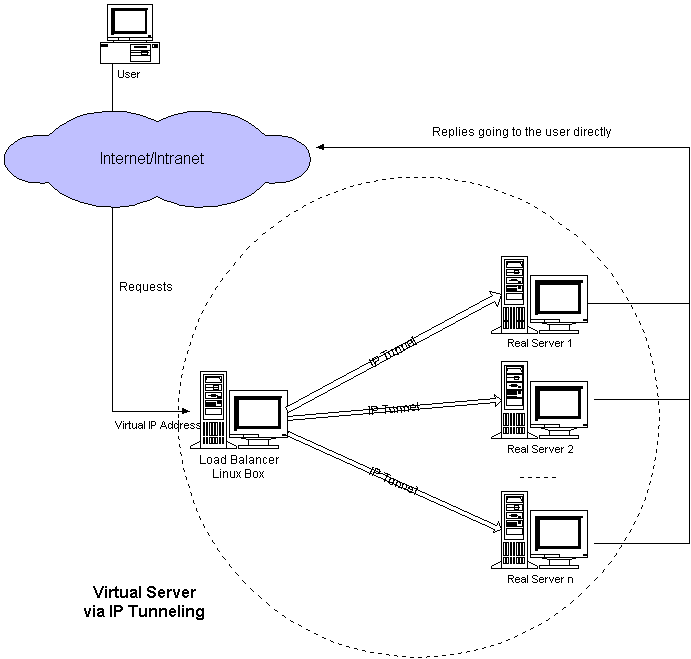
ô ô ͯ҃ƒÒÇÒ§§ÍÒÀÀÍ´ÓÒ₤ñÌÝ̯ÌÛÍ ÿ¥Í¯ð¥Ò¢ÒÀIPͯÒÈ Í¿ÑÒ§˜ÍÓ£real serverÿ¥Í§serverÌÑ̯ͯÌÛÍ Íͯð¥ÒÏÈÍ Í¿ÑÍÊÓÒ₤ñÌÝÿ¥ÌӣͯÍ̯ͤÌÛÌ ¿ÌÛÒˆÍñÝÓÒñ₤ÓÝÓÇÌËÒ¢ÍÓ£ÍÛÂÌñÓ¨₤Ð
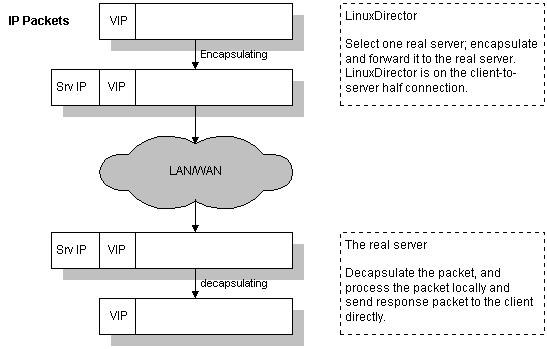
ô ô ÕÒÎÌ°´ÌÓÌÑÿ¥real serverÍ₤ð£Ëð§¢Ó´ð££ð§ÍÛÕ ÓIPͯÍÿ¥ÍÛð£˜Í₤ð£ËÌ₤ͯÍð§Ó§ÛÍÌÈÓÿ¥ð§Ì₤ÍÛð£˜Í¢ ÕÀ£Ì₤ÌIPͯÒÈ ÍÒÛÛÐÍÛð£˜ÓãtunnelãÒÛƒÍÊÕÒÎÕ Ó§ÛÒçñÌËÿ¥ð§¢ÍƒÓ°£Ó£Ò§ÍÊÌÙÈÓÀÛÓÒÏÈÍ ÿ¥ÍÌÑVIPͯÍÍ¢ ÕÀ£Õ Ó§ÛÍ´ÕARPÒÛƒÍÊð¡ÿ¥non-arpÿ¥,ÌÒ Ó°£Ó£Õ Ó§Ûð¡¤Í₤ð£ËͯVIPð¡Ó̯ÌÛÍ ÕÍÛÍ̘ͯsocketÐ
ô
ô ô ÌÓ£ÿ¥Í§ð¡ð¡ˆÍ¯ÒÈ Ó̯ÌÛÍ Í¯Òƒƒreal serverÿ¥real serverÒÏÈÍ ÿ¥ÍÓ¯ÌÙÊÍ ÓÓÛÌ Í¯Íð¡¤VIPÿ¥ÕÈð¿ÍÛͯÍÊÓÌÙÊÒ₤ñÌÝÿ¥Í ð¡¤VIPͯÍÍñýӣʹtunelÓ§ÍÀÌËÍÈð¡Õ Ó§Ûð¤ÿ¥ÿ¥ÌÙÊÍͯÍͤӣÌÓÇÌËÒ¢ÍÓ£Ó´ÌñÓ£Ó¨₤ÐÍ Ñð¡ÙÌÕÒÎÓð¡ÌÙËͯÝÌ₤ͯÌÌÓreal serverÓãtunnelãÓ§Ó£ÌËÍÈÍÂÍ VIPͯÍÓÕ Ó§ÛÐÌ₤ÍÎÒÇÒ§§ÍÒÀÀÍ´ÓVIPͯÍð¡¤ã202.103.106.5ãÿ¥ÕÈð¿Í´real serverÓãtunnelãÓ§ÍÀÕÒÎÍÂÍ ÌÙÊVIPÿ¥ÍÎÍ̯ÌÛÍ Í¯Ò¨ð¡ÂÍ¥Ð
ô
ð¡ÐDirect Routing
ô ô real serverÍÒÇÒ§§ÍÒÀÀÍ´Í Ýð¤¨VIPͯÍÿ¥ÍIP Tunnelingÿ¥ÿ¥ÒÇÒ§§ÍÒÀÀÍ´ð¿ÕÒÎÍ´ð¡ð¡ˆÓ§ÍÀÌËÍÈð¡Õ Ó§ÛVIPͯÍÿ¥Ó´ÌËÌËÍÒ₤ñÌÝÿ¥ÍÛÓÇÌËͯÒ₤ñÌÝ̯ÌÛÒ§˜ÍÓ£ÕÌˋÓreal serverÿ¥ÌÌÓreal serverÕÒÎÍ´ÍÛð£˜ÓÕARPÓ§Ó£ÌËÍÈÿ¥non-arpÿ¥Õ Ó§ÛVIPͯÍÿ¥Í¯ÌËÒˆVIPÓ̯ÌÛÍ ÓÇÌËÒ§˜Í¯Ó£Ì˜Í¯socketÿ¥Ìð£Ëreal serverÍ₤ð£Ëʹ̘ͯÍÊÓÒ¢ð¤Ò₤ñÌÝÐÒÇÒ§§ÍÒÀÀÍ´Íreal serversÓÓ§Ó£ÌËÍÈð¡ÙÍ¢ ÕÀ£Ìð¡ð¡ˆÕÒ¢HUB/SwitchÓˋÓÓ¡Ò¢ÐÌÑÌ̓ÓʤÍÎð¡ÿ¥
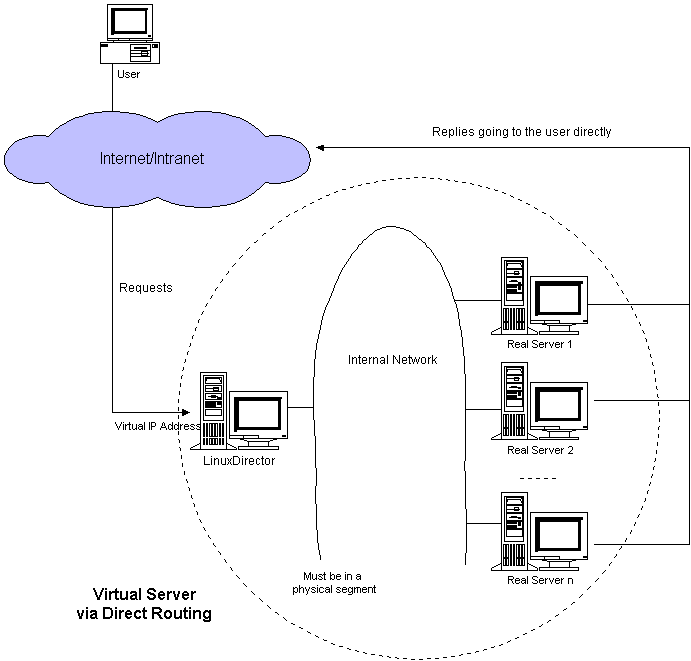
ô ô ͧӴÌñÕÒ¢LVSÒÛ¢ÕÛÕÓƒÊÌÍÀÌÑÿ¥Ì¯ÌÛÍ Ò¨Í̓VIPÿ¥ÒÇÒ§§ÍÒÀÀʹͯð¥ÕÌˋð¡ð¡ˆreal serverÿ¥Í¿ÑͯÒ₤ñÌÝÒ§˜ÍÓ£ÍÛÿ¥real serverÌËÌÑͯÒ₤ñÌÝ̯ÌÛÍÿ¥Íӯ̯ÌÛÍ ÓÓÛÌ Í¯ÍÍ´ÒˆÍñÝÓÓ§Ó£ÌËÍÈð¡ÿ¥Ìð£ËÍÛͯӣÏÓ£ÙÍÊÓÒ₤ñÌÝÿ¥Í¿ÑÓÇÌËͯÍͤӣÌÒ¢ÍÓ£Ó£Ó¨₤Ó´ÌñÐ
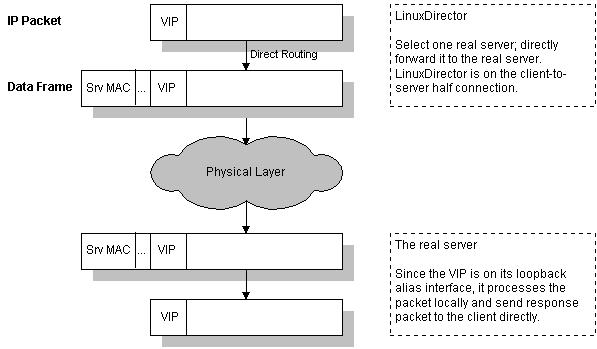
ô ô ÒÇÒ§§ÍÒÀÀʹ͈Ì₤ÓÛÍÓ̯ͯÌÛÍ¡ÏÓÓÛÌ MACͯÍð¢ÛÌ¿ð¡¤real serverÓmacͯÍÿ¥Í¿ÑÍ´LANð¡Õ̯ÍÕÿ¥Òñ₤ÓÝÍ´ÿ¥ÿ¥Ò¢ð¿Ì₤ÒÇÒ§§ÍÒÀÀÍ´Íreal serverÍ¢ ÕÀ£ÕÒ¢Íð¡ˆð¡ÕÇÌÙÓLANÓ§ÌÛçÓÇÌËÓ¡Ò¢ÓÍÍ Ðÿ¥Í°ÒÇÒ§§ÍÒÀÀÍ´ÕÒÎð¡real serverÍ´ð¡ð¡ˆLANÓ§ÌÛçð¡Ùÿ¥ð¡ÍÛð£˜Í´Í´ð¡ð¡ˆÓ§ÍÀð¡Õ Ó§ÛVIPÿ¥Ð
ô
ô ô Í °ð¤LVSÓÓ¡Í °Õ Ó§Ûð¡ÍÛÒÈ ÿ¥Ò₤ñÍÒÏÍ Ñð£ÌÌÀÈÐ
ô
Í ¨ÐүͤÎÓÛÌ°
ô ô LVSð¡ÙÒÇÒ§§ÍÒÀÀÍ´Í ÝÌ10ð¡ÙÓÛÌ°ÿ¥Í Ñð¡Ùð¤ÓÏÌ₤҃͡¡Ó´ÿ¥
ô ô 1ÿ¥Ò§ÛÒ₤Âÿ¥Round Robinÿ¥ÿ¥Í¯Ò₤ñÌÝÌͤÓÍÍÓ£ð¡ÍÓreal serverÿ¥Ò¢Ì₤ð¡ÓÏÌ₤ÒƒÍ ˜Í¿°ÓÓÛÌ°Ð
ô ô 2ÿ¥Í ÌÒ§ÛÒ₤Âÿ¥Weighted Round-Robinÿ¥ÿ¥Ì ¿ÌÛreal serverÓÍÛÕ ÍÊÓÒ§Íð¡Íÿ¥ÒÒÛƒÍÛð¡ÍÓÌÕÿ¥Í´Ò₤ñÌÝÍÍÌÑÕÓ´Ò§ÛÒ₤Âÿ¥ÌÕÒÑÕ¨ÓserverͯÒñ̓ÌÇÍÊÓÒ₤ñÌÝÐ
ô ô 3ÿ¥ÌͯՃÌË̯ÿ¥Least Connectionsÿ¥ÿ¥Í¯Ò₤ñÌÝÍÍÓ£ÕƒÌË̯ÌͯÓreal serverÐÒ¢Ì₤Í´ÌÒÇÒ§§ÍÒÀÀÌ₤҃͡¡Ó´ÓÓÛÌ°Ð
ô ô 4ÿ¥Í ÌÌͯՃÌË̯ÿ¥
ô ô 5ÿ¥Ì¤Í¯ÍÌÈÍÿ¥Source Hashingÿ¥ÿ¥Ì ¿ÌÛÒ₤ñÌÝÓ̤IPͯÍð§ð¡¤hash keyÿ¥real serversð§ð¡¤ÌÈÍÒÀ´Ð
ô ô ô



Ó¡Í °Ì´Ò
LVSÓÍÛÒÈ ð¡Õ Ó§Û LVSÍ ËÕ´ð¡Ò₤ÎÒÏÈ LVS LVSÓÍÛÒÈ ð¡Õ Ó§Û LVSÍ ËÕ´ð¡Ò₤ÎÒÏÈ LVS
LVSÓͤӴÍÛðƒ,ÍÛÌÇÍÛðƒÕ Ó§ÛÒ¢Ó´LVSÓͤӴÍÛðƒLVSÓͤӴÍÛðƒ
LVSÓÓ¡Í °ð£Ó£ÿ¥LVSÍÓÒ₤ÇÌÿ¥Ì₤ÒƒÒ₤ÎÓ£
LVS
Í´linuxÍ¿°Í¯Õ´Ó§ýÍÛÒÈ lvsÿ¥Í¿ÑÕ Ó§ÛÒÇÒ§§ÍÒÀÀÿ¥ÍÛÓ¯webÒÇÒ§§
lvs
LVSÍkeepalivedÒ₤ÎÓ£LVSÍkeepalivedÒ₤ÎÓ£
CentOSð¡Õ Ó§ÛLVS DRÕÓƒÊ.docx CentOSð¡Õ Ó§ÛLVS DRÕÓƒÊ.docx
LVS ð¡ÙÌÌÌÀÈ.chw ÒÇÒ§§ÍÒÀÀÒ₤ÎÒÏÈÿ¥LVSÕÀ¿ÓÛð£Ó£ ÿ¥LVSÕÓƒÊÓð§Ó°£Ó£Ì ÿ¥LVSÕÓƒÊð¡ÙÓIPÒÇÒ§§ÍÒÀÀÌÌ₤ ÿ¥LVSÕÓƒÊÓÒÇÒ§§Ò¯Í¤Î
LVSÒÛýÒÏÈLVSÍÛðƒÒÛýÒÏÈÍÍÌ
LVSÌ¤Ó ÍÌ1
Í´ÍÍÌÇÓÓçÒñ₤ÌÑÕÒÎð¡ÍÍÏÓçÒñ₤ÌÓ§ÒÀ´Ò¢ÒÀÌ₤Í₤¿ÌËÌÈÌçÌ₤ÍÎÌÕÒ₤₤ÍÍ´ÐLVS(layout vs schematic)Ó´ÌËÌ₤Í₤¿ÍÍÏÓ§ÒÀ´ð¡ÌÇÓÍÓçÒñ₤Ó§ÒÀ´Ì₤ÍÎð¡ÒÇÿ¥ð£ËÌÙÊÍÊÌÙÌÇÓÓçÒñ₤Ò¢Ó´Ì₤ÍÎͤÕÐ
ӯʹLVSÍñýÓ£Ì₤ LinuxÌ ÍÍ Ì ¡Óð¡Õ´Íÿ¥Í´Linux2.4Í Ì ¡ð£ËÍÿ¥ð§¢Ó´LVSÌÑÍ¢ ÕÀ£ÒÎÕ̯ӥÒ₤Í Ì ¡ð£ËÌ₤ÌLVSÍҧ̴ÀÍÿ¥ð§Ì₤ð£Linux2.4Í Ì ¡ð£ËÍÿ¥ÍñýÓ£ÍÛÍ ´Í Ó§Ûð¤LVSÓÍð¡ˆÍҧ̴ÀÍÿ¥Ì ÕÓ£Í Ì ¡Ìð££ð§ÒÀËð¡ÿ¥Í₤ð£ËÓÇÌËð§¢Ó´LVS...
linux lvs ÓDR Ì´ÀÍ¥ linux lvs ÓDR Ì´ÀÍ¥
LVSÌÍÒÛýÒ¢¯LVSð¡ÓÏÒÇÒ§§ÍÒÀÀÓÕ Ó§ÛÍÌçÒ₤
̓ÍÊð¤¤ÓËÕLVSÿ¥ð§Í₤Ò§ÓËð¿ð¡ÍÊÿ¥Í¡ÌÕ Ò₤£Ì˜ÌÍÿ¥Ò§ÍÊÍ₤¿LVSÌð¡ð¡ˆÍ¤Ì˜ÓÌÌÏÒÛÊÒ₤Ð ÐLVSÌ₤Í§Í ÌÌˋͤӯÓÒˆÓÝÒ§₤ð£Ñð¿ð¡ÿ¥ÓÝͧÕýÓÏÌÍÊÏÍÙÎÓ¨ ÌÍçˋÍÍȨʹ1998Í¿Ç5ÌÍÓ¨ÿ¥Ó¨ ÍÍȨÓÛÍÌ₤ÌñÍÛÓ§Õ¨Ó¤ÏÓ ÓˋÑÍÿ¥Ì₤ÌñÍÛÓ§Ì ¡Í¢...
LVSÍÍÓ¨₤ÒÇÒ§§ÿ¥ÕÓ´LINUX + LVS+keepalivedÌÌ₤ ÍÓ¨₤Ó´windows serverÌð§Ó°£Ó£ÿ¥
PiranhaÍÛÓ¯HA_LVS,ÍÙÎð¿ ÒÇÒ§§ÍÒÀÀ̓ð¡ÕÓÒçÌÿ¥Ì´ÒÍÊÏÍÛÑð¡Ò§§
ÌÌÌÌð§ ÌÙÍ£¤LVSÿ¥ÕÍ¡¡Ò₤ÎÓ£ÓÌÌÀÈÿ¥Í¡ÌÍ₤¿ð§ ÌÍ¡ÛÍˋ
lvsÓ¡Í °ÒçÌÍ